Shut down idle clusters
Turning off resources you’re no longer using (idle clusters) is the easiest target to eliminate overspending. Most enterprises already have a way to do this automatically, and this is something the cloud data providers and platforms (AWS, Google Cloud Platform, Microsoft Azure, databricks) have started to take responsibility for. Most of the better so-called cost-management solutions do a good job of identifying and auto-terminating idle resources.
If you do not already have an automated way to terminate resources no longer in use, employ one immediately. At enterprise level, the savings can be enormous—we’ve seen companies save millions.
Right-size resources at job level
Most cost-optimization opportunities are not visible (like idle clusters), but are hidden below the surface. It’s down in the weeds, in the code and configuration details, where there’s the biggest chunk of overspending.
One of the two biggest reasons (inefficient code being the other) is oversized resources.
Oversized resources are simply where a data engineer (or lots of data engineers) requested more resources from the cloud provider than are actually needed to run the job successfully. Of course, they’re not wasting money intentionally. They don’t want to get caught short and not have enough compute, memory, storage to run their jobs, so they “guesstimate”—and invariably overshoot.
This happens thousands of times a month. The data engineers simply don’t have the information at hand to specify the most cost-effective configuration, nor do they have the time or expertise to get that information anything nearing quickly. Very few people do.
Even a Fortune 500 enterprise like MegaBankCorp can count on one hand the number of people with enough expertise to “right-size” the bank’s cloud data jobs or applications. There just aren’t enough of these people to tackle the problem at scale.
What DataFinOps AI does is analyze everything that’s running, pinpoint among the thousands of jobs where the number, size, type of resources you’re using is more than you need, calculate the cost implications, and deliver up a prescriptive recommendation (in plain English) for a more cost-effective configuration.
Here, MegaBankCorp engineers can double-click from the dashboard into an AI analysis with recommended remediation actions. Here, the AI has identified a more cost-effective configuration for the job at hand, based on real-time data. The AI recommendation specifies exactly what type of resource, with exactly how much memory and how many cores, would be less expensive and still get the job done. It’s not quite a self-healing system, but it’s pretty close.

Image courtesy of Unravel
Find and fix inefficient code
Code problems are the other big reason for overspending at the job level. MegaBankCorp has a couple of thousand data engineers committing code weekly, daily, hourly. A lot of it involves moving workloads from the on-prem Cloudera/Hadoop environment to Databricks. Sammi and his team leaders try to do code checks as best they can, but they’re shoveling sand against the tide.
Yet inefficient code drives up costs, sometimes astronomically. We know of one case where a bad join ran over the weekend and wound up costing the company over $500,000 for a job that not only never completed but should never have seen the light of day in the first place.
Below, one of the jobs fueling Jon’s Fraud Detection workloads has some bad joins that affected five different queries. The AI has identified these problematic issues and performs an automated root cause analysis to point directly to what in the code needs to be optimized.
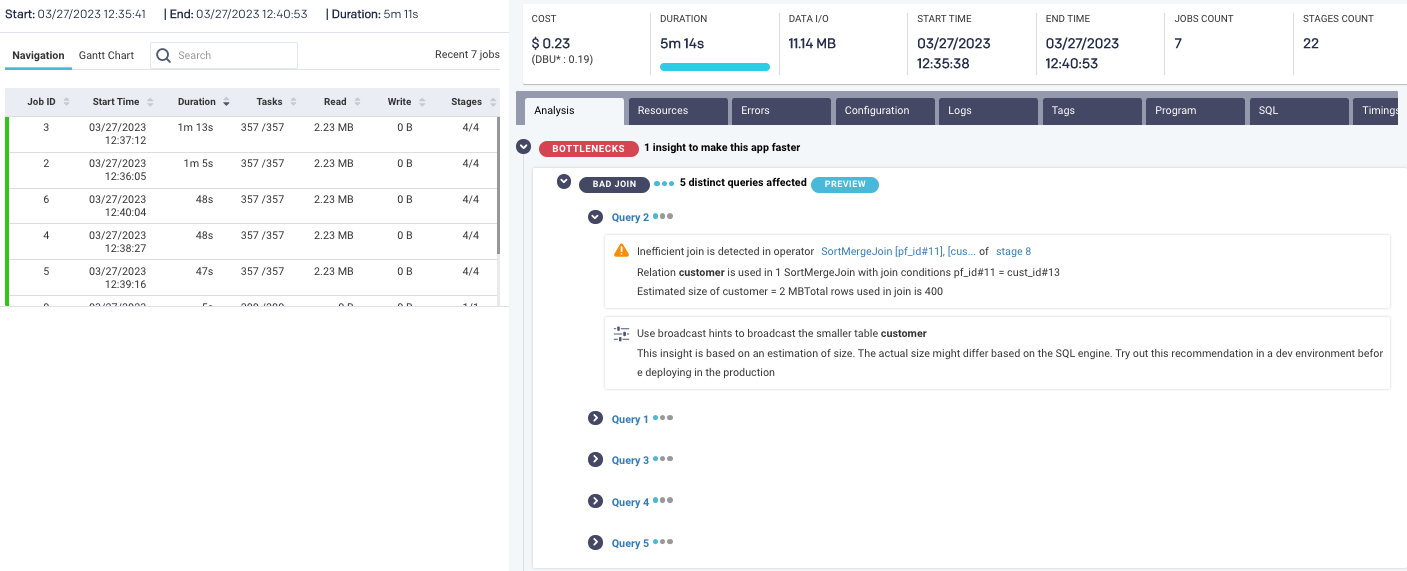
Image courtesy of Unravel
Find out more about how automated AI prescriptive recommendations work at Unravel’s 3-minute demo video or the self-guided tour, Job-Level Recommendations, here.
Optimize at the cluster level
Additional cloud data cost optimization opportunities are found at the cluster level.
The same performance and financial data can be analyzed (again, most helpfully with AI) to uncover places where you don’t even know you’re wasting money.
Three areas where a DataFinOps approach can ensure that the company is spending its cloud data budget wisely and efficiently at the cluster level:
- Auto-scaling more intelligently
- Choosing the right cloud pricing model for the task at hand
- Leveraging spot instance discounts
See what automated cost optimization at the cluster level looks like in Unravel’s Allocated Cloud Cost Optimization 3-minute demo video or self-guided product capability tour here.
Auto-scale more intelligently
The cloud’s elasticity is great but comes at a cost, and isn’t always needed. AI analyzes usage trends to help predict when auto-scaling is appropriate—or when rescheduling the job may be a more cost-effective option.
Every cloud provider has auto-scaling options. But what should you auto-scale, to what, and when? MegaBankCorp leveraged the DataFinOps AI to understand trends and usage and access to help Raj (and Sammi) predict and see the days of the week and times of day when auto-scaling is appropriate (or find better times to run jobs). Workload heatmaps based on actual usage make it easy to visualize when, where, and how to scale resources intelligently.
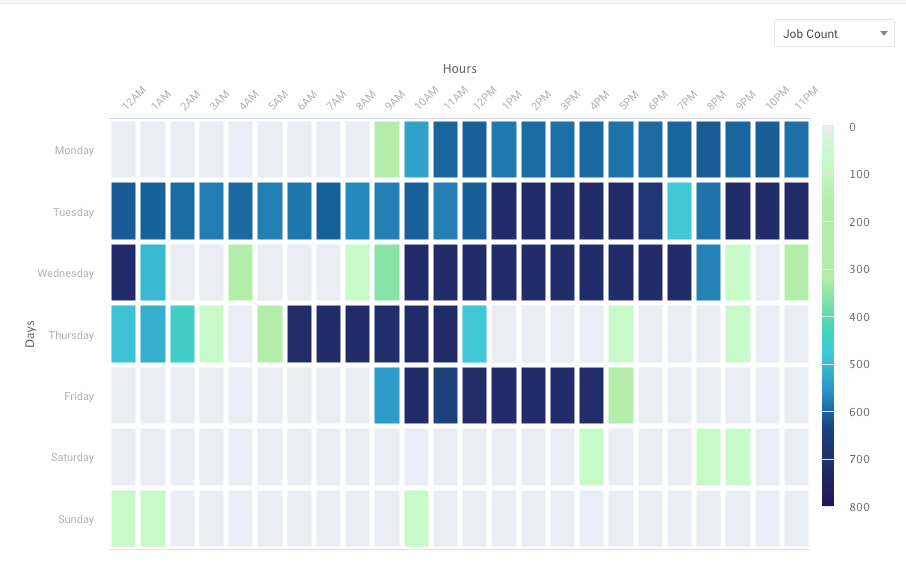
Image courtesy of Unravel
Choose the right cloud pricing model for the task at hand
For many data applications, MegaBankCorp wants and needs the elasticity and scalability afforded by the cloud but also needs the workloads to be running full time, all the time. Like many companies, MegaBankCorp started their cloud journey using a pay-as-you-go pricing model but soon found it got very pricey very fast.
They realized significant savings by pre-paying to reserve instances of “always on” infrastructure that they knew they’d need. All the data cloud providers—Amazon, Google, Azure, Databricks, Snowflake—offer various discount pricing packages when you commit to a certain amount of usage. The greater your commitment, the steeper your discount.
Leverage spot instance discounts
You can save a lot of money—up to 90% off—with spot instances if you can identify the right kind of jobs to run. While the deep discounts are extremely attractive, not every application or workload is a good fit for spot instances (an Amazon term, called spot VMs in Google and Azure). Spot instance discounts come with the caveat that the cloud provider can “pull the plug” and terminate the instance with as little as a 30-second warning.
You might actually increase costs if you try to run a complex, multi-step workflow on spot and lose access to the instance before the job finishes—you’ll have to run it again, either taking the same gamble on spot or (more likely) using reserved instance resources.
Knowing which jobs are good candidates to run on spot instances is tricky without having fine-grained clarity into your application or workload profile. Only by understanding actual usage requirements—CPU, memory, I/O, duration, containers, etc.—can you identify what can be run safely on spot.
This is where business priorities come strongly into play—a high degree of reliability (and safety) may well trump potential pricing discounts.
But smaller jobs that complete pretty quickly may be perfectly suited for leveraging these deep discounts.
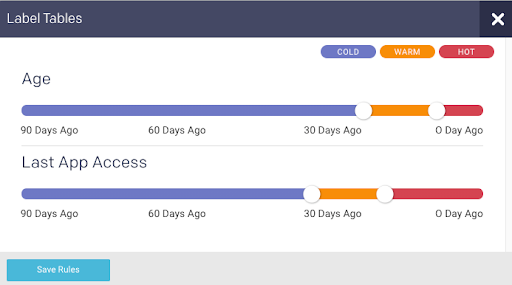
Data tiering
MegaBankCorp has petabytes of data, but isn’t using all of it all of the time. Sammi and Raj looked at which datasets are (not) being used, applying cold/warm/hot labels based on age or usage. They wanted to understand which ones haven’t been touched in months yet still sit on expensive storage. Moving cold data to less-expensive options saved MegaBankCorp 80-90% on storage costs.